Today, the landscape of large language models (LLMs) is rich with diverse evaluation benchmarks. In this blog post, we’ll explore the various benchmarks used to assess language models and guide you through the process of obtaining these benchmarks after running a language model.
Benchmarks for evaluating large language models come in various forms, each serving a unique purpose. They can be broadly categorized into general benchmarks, which assess overall performance, and specialized benchmarks, designed to evaluate the model’s proficiency in specific areas such as understanding the Chinese language or its ability to perform function calls.
Consider to learn Stanford CS224U if you want to learn more fundamental knowledge about the LLM evaluation.
LLM leaderboard
Numerous leaderboards exist for Large Language Models (LLMs), each compiled based on the benchmarks of these models. By examining these leaderboards, we can identify which benchmarks are particularly effective and informative for evaluating the capabilities of LLMs.
Also, we can get more benchmark from the papers for sure. 📝 Paper: Evaluating Large Language Models: A Comprehensive Survey can provide a full explanation about it.
Classification of LLM evaluation
There are different benchmarks for the LLM evaluation. The general classification can be found in Figure 1.
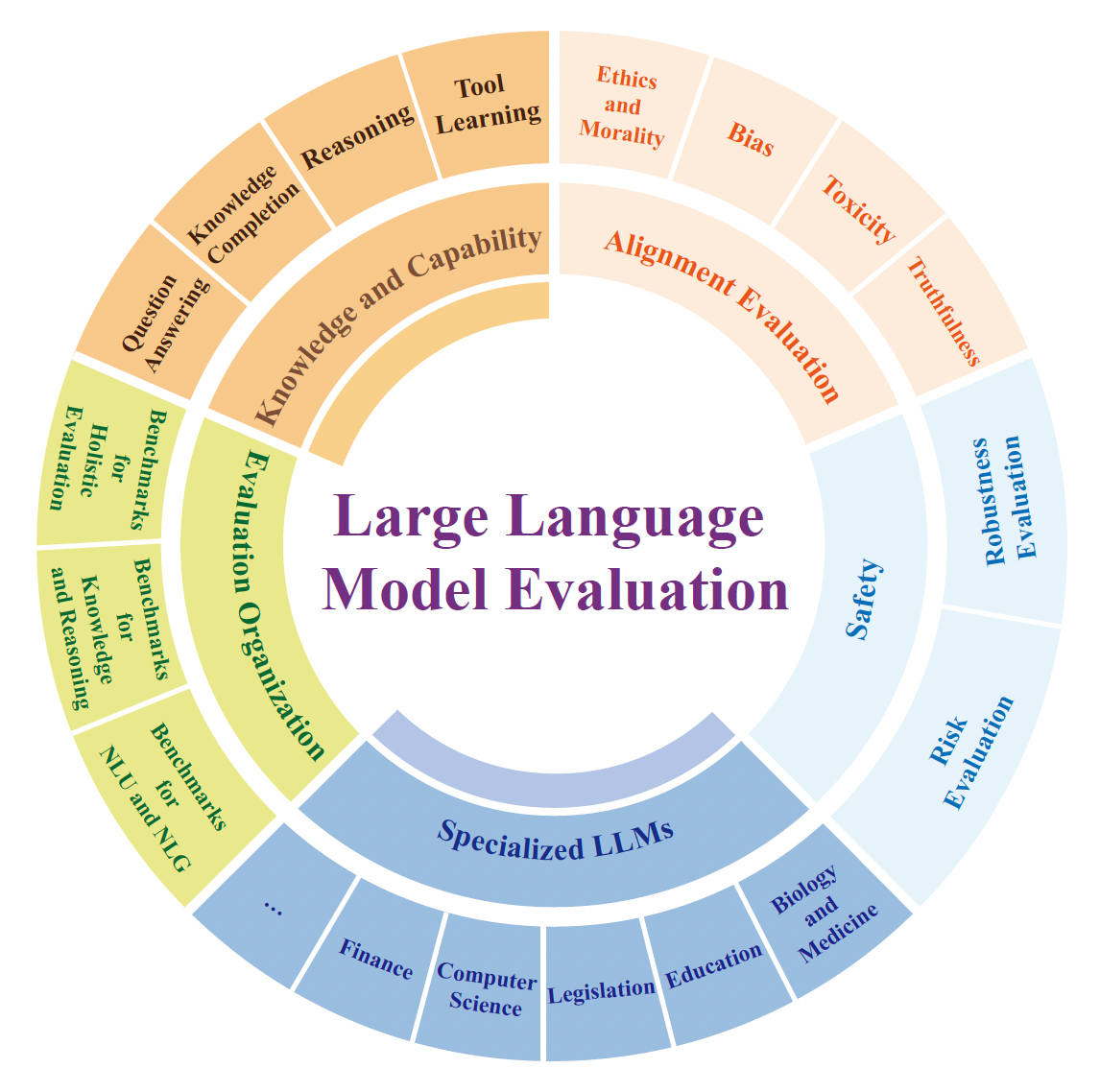
For each aspect of the model, we will have different methods to evaluate it.
The knowledge and capability evaluation can be seen in Figure 2.
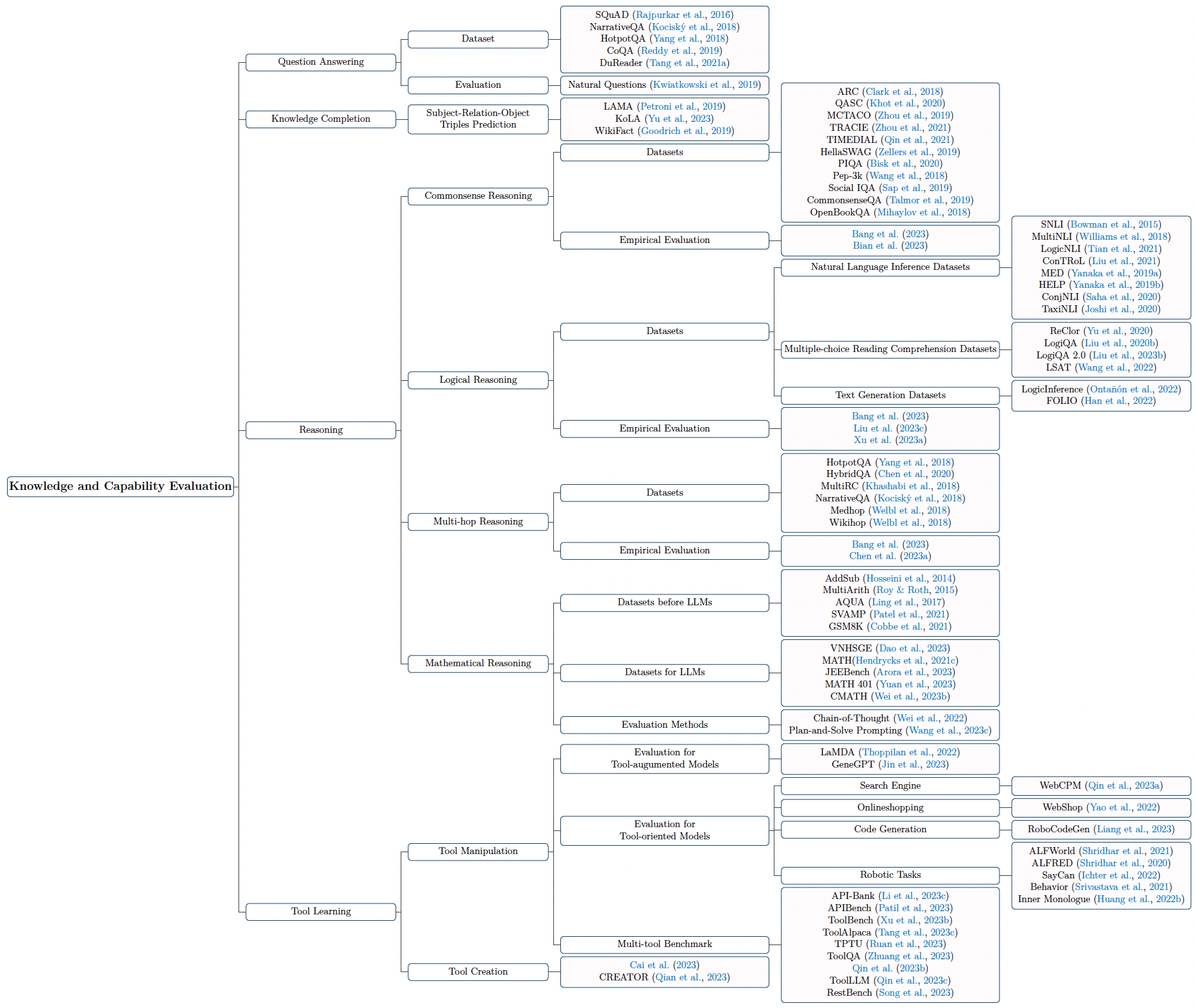
The commonsense reasoning datasets can be seen below:
| Dataset | Domain | Size | Source | Task |
|---|---|---|---|---|
| ARC | science | 7,787 | a variety of sources | multiple-choice QA |
| QASC | science | 9,980 | human-authored | multiple-choice QA |
| MCTACO | temporal | 1,893 | MultiRC | multiple-choice QA |
| TRACIE | temporal | - | ROCStories, Wikipedia | multiple-choice QA |
| TIMEDIAL | temporal | 1.1K | DailyDialog | multiple-choice QA |
| HellaSWAG | event | 20K | ActivityNet, WikiHow | multiple-choice QA |
| PIQA | physical | 21K | human-authored | 2-choice QA |
| Pep-3k | physical | 3,062 | human-authored | 2-choice QA |
| Social IQA | social | 38K | human-authored | multiple-choice QA |
| CommonsenseQA | generic | 12,247 | CONCEPTNET, human-authored | multiple-choice QA |
| OpenBookQA | generic | 6K | WorldTree | multiple-choice QA |
And the multi-hop reasoning dataset is:
| Dataset | Domain | Size | # hops | Source | Answer type |
|---|---|---|---|---|---|
| HotpotQA | generic | 112,779 | 1/2/3 | Wikipedia | span |
| HybridQA | generic | 69,611 | 2/3 | Wikitables, Wikipedia | span |
| MultiRC | generic | 9,872 | 2.37 | Multiple | MCQ |
| NarrativeQA | fiction | 46,765 | - | Multiple | generative |
| Medhop | medline | 2,508 | - | Medline | MCQ |
| Wikihop | generic | 51,318 | - | Wikipedia | MCQ |
Like the knowledge and capability, there are datasets prepared for other benchmark as well.
Benchmarks
Once we’ve acquired the dataset to assess the Large Language Model (LLM), we introduce a crucial concept known as a benchmark—a tool that quantitatively evaluates the LLM’s performance. Let’s delve deeper into the benchmarks and their significance.
| Benchmarks | # Tasks | Language | # Instances | Evaluation Form |
|---|---|---|---|---|
| MMLU | 57 | English | 15,908 | Local |
| MMCU | 51 | Chinese | 11,900 | Local |
| C-Eval | 52 | Chinese | 13,948 | Online |
| AGIEval | 20 | English, Chinese | 8,062 | Local |
| M3KE | 71 | Chinese | 20,477 | Local |
| M3Exam | 4 | English and others | 12,317 | Local |
| CMMLU | 67 | Chinese | 11,528 | Local |
| LucyEval | 55 | Chinese | 11,000 | Online |
Also, there are some benchmark for the holistic evaluation.
| Benchmarks | Language | benchmark | Evaluation Form | Expandability |
|---|---|---|---|---|
| HELM | English | Automatic | Local | Supported |
| BIG-bench | English and others | Automatic | Local | Supported |
| OpenCompass | English and others | Automatic and LLMs-based | Local | Supported |
| Huggingface | English | Automatic | Local | Unsupported |
| FlagEval | English and others | Automatic and Manual | Local and Online | Unsupported |
| OpenEval | Chinese | Automatic | Local | Supported |
| Chatbot Arena | English and others | Manual | Online | Supported |
How to calculate the benchmark
In the dynamic world of artificial intelligence, benchmarks play a pivotal role in gauging the prowess of AI models. A notable platform that has garnered widespread attention for its comprehensive leaderboard is Hugging Face. Here, benchmarks such as Average, ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K offer a bird’s-eye view of an AI model’s capabilities. To demystify the process of benchmark calculation, let’s delve into a practical example using the TruthfulQA benchmark.
Discovering TruthfulQA
The TruthfulQA dataset, accessible on Hugging Face (view dataset), serves as an excellent starting point. This benchmark is designed to evaluate an AI’s ability to not only generate accurate answers but also ensure they align with factual correctness.
Unified Framework for Evaluation
Thankfully, the complexity of working across different benchmarks is significantly reduced with tools like the lm-evaluation-harness repository. This unified framework simplifies the evaluation process, allowing for a streamlined approach to assessing AI models across various benchmarks.
Tailoring Evaluation to Learning Scenarios
The evaluation process varies significantly depending on the learning scenario—be it zero-shot or few-shot learning. In few-shot learning, where the model is primed with examples, prompts such as thus, the choice is: can guide the model to the correct answer format (e.g., A, B, C). For zero-shot scenarios, where the model lacks prior examples, multiple prompts may be necessary. The first prompt elicits a raw response, while subsequent prompts refine this into a final, decisive choice.
Conclusion
Benchmarks like TruthfulQA are indispensable for advancing AI research, providing a clear benchmark for evaluating the nuanced capabilities of AI models. By leveraging unified frameworks and adapting to the specific demands of different learning scenarios, researchers can efficiently and accurately assess their models. Remember, the key to a successful evaluation lies in understanding the dataset, choosing the right learning scenario, and meticulously following the evaluation protocol to ensure fair and accurate results.